高可用
Seata的TC服务作为分布式事务核心,一定要保证集群的高可用性。
一、高可用架构模型
搭建TC服务集群非常简单,启动多个TC服务,注册到nacos即可。
但集群并不能确保100%安全,万一集群所在机房故障怎么办?所以如果要求较高,一般都会做异地多机房容灾。
比如一个TC集群在上海,另一个TC集群在杭州:
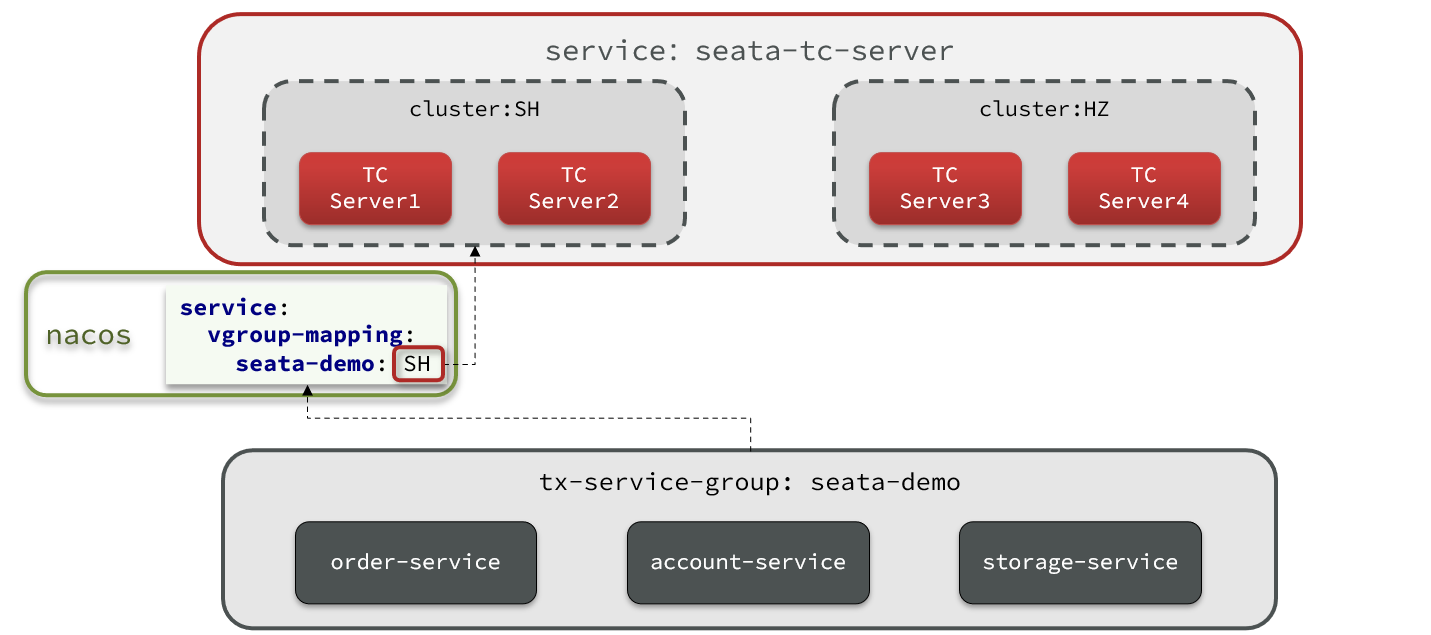
微服务基于事务组(tx-service-group)与TC集群的映射关系,来查找当前应该使用哪个TC集群。当SH集群故障时,只需要将vgroup-mapping中的映射关系改成HZ。则所有微服务就会切换到HZ的TC集群了。
二、TC服务的高可用和异地容灾
1.模拟异地容灾的TC集群
计划启动两台seata的tc服务节点:
| 节点名称 | ip地址 | 端口号 | 集群名称 |
|---|---|---|---|
| seata | 127.0.0.1 | 8091 | SH |
| seata2 | 127.0.0.1 | 8092 | HZ |
之前我们已经启动了一台seata服务,端口是8091,集群名为SH。
准备docker-compose.yaml文件
只要保持配置一致,seata服务可在一台机器上部署多实例,也可同时部署在多台不同的主机下面实现服务高可用
version: "3.1"
services:
seata-server-1:
image: seataio/seata-server:1.6.1
ports:
- "7091:7091"
- "8091:8091"
environment:
- STORE_MODE=db
# 以SEATA_IP作为host注册seata server
- SEATA_IP=seata_ip
- SEATA_PORT=8091
volumes:
- "/usr/share/zoneinfo/Asia/Shanghai:/etc/localtime" #设置系统时区
- "/usr/share/zoneinfo/Asia/Shanghai:/etc/timezone" #设置时区
# 假设我们通过docker cp命令把资源文件拷贝到相对路径`./seata-server/resources`中
# 如有问题,请阅读上面的[注意事项]以及[使用自定义配置文件]
- "./seata-server/resources:/seata-server/resources"
seata-server-2:
image: seataio/seata-server:1.6.1
ports:
- "7092:7091"
- "8092:8092"
environment:
- STORE_MODE=db
# 以SEATA_IP作为host注册seata server
- SEATA_IP=seata_ip
- SEATA_PORT=8092
volumes:
- "/usr/share/zoneinfo/Asia/Shanghai:/etc/localtime" #设置系统时区
- "/usr/share/zoneinfo/Asia/Shanghai:/etc/timezone" #设置时区
# 假设我们通过docker cp命令把资源文件拷贝到相对路径`./seata-server/resources`中
# 如有问题,请阅读上面的[注意事项]以及[使用自定义配置文件]
- "./seata-server/resources:/seata-server/resources"
# seata服务3......seata服务N
2.seata高可用部署tc服务器,数据库需要共用一个吗?
在 Seata 的高可用部署中,事务协调器 (Transaction Coordinator, TC) 的数据库是需要共用一个的。Seata 的架构设计中,TC 负责管理全局事务的状态,如果有多个 TC 实例部署在集群中,它们需要共享同一个数据库,以便于协调和管理事务的一致性。
具体原因如下:
- 全局事务管理:Seata 中的 TC 需要记录全局事务的状态和分支事务的信息。如果多个 TC 实例使用不同的数据库,会导致事务状态不一致的问题,无法正确协调事务的提交和回滚。
- 故障切换:在高可用部署中,如果一个 TC 实例宕机,其他实例可以接管它的事务处理。如果这些实例不共用一个数据库,它们将无法获取当前事务的状态,无法进行正确的故障恢复和接管操作。
- 数据一致性:共享同一个数据库可以保证所有 TC 实例对全局事务和分支事务的视图是一致的,确保在并发情况下事务管理的正确性和一致性。
因此,在 Seata 高可用部署中,所有的 TC 实例应该配置为使用同一个数据库,以确保全局事务的正确管理和系统的高可用性。
3.将事务组映射配置到nacos
接下来,我们需要将tx-service-group与cluster的映射关系都配置到nacos配置中心。
新建一个配置:
配置的内容如下:
# 事务组映射关系
service.vgroupMapping.seata-demo=SH
service.enableDegrade=false
service.disableGlobalTransaction=false
# 与TC服务的通信配置
transport.type=TCP
transport.server=NIO
transport.heartbeat=true
transport.enableClientBatchSendRequest=false
transport.threadFactory.bossThreadPrefix=NettyBoss
transport.threadFactory.workerThreadPrefix=NettyServerNIOWorker
transport.threadFactory.serverExecutorThreadPrefix=NettyServerBizHandler
transport.threadFactory.shareBossWorker=false
transport.threadFactory.clientSelectorThreadPrefix=NettyClientSelector
transport.threadFactory.clientSelectorThreadSize=1
transport.threadFactory.clientWorkerThreadPrefix=NettyClientWorkerThread
transport.threadFactory.bossThreadSize=1
transport.threadFactory.workerThreadSize=default
transport.shutdown.wait=3
# RM配置
client.rm.asyncCommitBufferLimit=10000
client.rm.lock.retryInterval=10
client.rm.lock.retryTimes=30
client.rm.lock.retryPolicyBranchRollbackOnConflict=true
client.rm.reportRetryCount=5
client.rm.tableMetaCheckEnable=false
client.rm.tableMetaCheckerInterval=60000
client.rm.sqlParserType=druid
client.rm.reportSuccessEnable=false
client.rm.sagaBranchRegisterEnable=false
# TM配置
client.tm.commitRetryCount=5
client.tm.rollbackRetryCount=5
client.tm.defaultGlobalTransactionTimeout=60000
client.tm.degradeCheck=false
client.tm.degradeCheckAllowTimes=10
client.tm.degradeCheckPeriod=2000
# undo日志配置
client.undo.dataValidation=true
client.undo.logSerialization=jackson
client.undo.onlyCareUpdateColumns=true
client.undo.logTable=undo_log
client.undo.compress.enable=true
client.undo.compress.type=zip
client.undo.compress.threshold=64k
client.log.exceptionRate=100
4.微服务读取nacos配置
接下来,需要修改每一个微服务的application.yml文件,让微服务读取nacos中的client.properties文件:
seata:
config:
type: nacos
nacos:
server-addr: 127.0.0.1:8848
username: nacos
password: nacos
group: SEATA_GROUP
data-id: client.properties
重启微服务,现在微服务到底是连接tc的SH集群,还是tc的HZ集群,都统一由nacos的client.properties来决定了。